WebWeaver: Unleashing HTML Magic with HtmlAgilityPack
- Asiel Elaouare
- Automatisation
- December 9, 2023
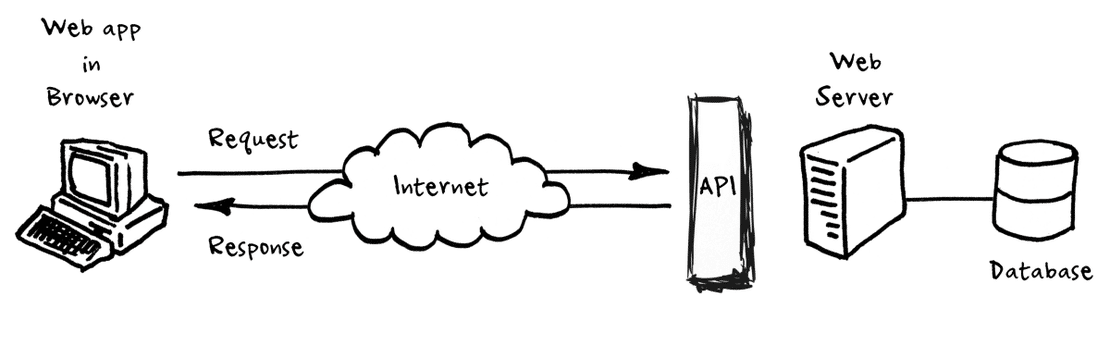
As I pondered my next coding projects for some hands-on practice, the idea of crafting a web scraper script caught my attention. While the basics might seem straightforward, I craved a challenge. That’s when the concept of a user-friendly console application struck me – one that not only prompts users for a URL to scrape but also lets them specify the type of information they want to extract. To take it a step further, I envisioned the seamless export of this valuable data to either a text file or a CSV file, giving users the flexibility to choose their preferred format.
I made some scraping scripts back with python, but this time I wanted to use C#. Therefore I had to use HtmlAgilityPack package and the System.IO library. I had to consult the documentation for this package since it was a bit confusing to use. I also watched a good tutorial beofore starting, to get a better idea of how the package works and what it has to offer.
The script starts by this method:
static HtmlDocument GetDocument(string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument htmlDocument = web.Load(url);
return htmlDocument;
}
The provided C# code defines a method named GetDocument that takes a URL as a parameter (this URL is given by the user), uses the HtmlAgilityPack library to load the HTML content from that URL, and returns an HtmlDocument object representing the parsed HTML.
Here’s a breakdown of what each part of the code does:
HtmlWeb web = new HtmlWeb();: This line creates an instance of the HtmlWeb class, which is part of the HtmlAgilityPack library. HtmlWeb is used to load HTML from a URL.
HtmlDocument htmlDocument = web.Load(url);: This line uses the Load method of the HtmlWeb class to download and parse the HTML content from the specified URL (url). The parsed HTML content is then stored in an HtmlDocument object named htmlDocument.
return htmlDocument;: Finally, the method returns the HtmlDocument object, which can be further processed or analyzed using methods provided by HtmlAgilityPack.
In summary, the GetDocument method encapsulates the logic for loading an HTML document from a given URL using HtmlAgilityPack, providing a convenient way to retrieve and work with the parsed HTML content in other parts of your code.
After writing some code and testing on a website to extract all the <li> nodes that contained a <a> with an atribute href="url" I encountered a problem that I couldn’t understand why it was happening, after some minutes of debugging I still couldn’t understand the cause of the issue that was thrown at line string href = link.Attributes["href"].Value; by the IDE. The error thrown was a System.NullReferenceException, I’ve ensured that linkNodes is not null before entering the foreach loop. Although, it still indicated that the link might be null.
static List<string> GetProductsLinks(string url)
{
List<string> productsLinks = new List<string>();
HtmlDocument htmlDocuent = GetDocument(url);
HtmlNodeCollection linkNodes = htmlDocuent.DocumentNode.SelectNodes("//li/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
productsLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return productsLinks;
}
After a bit of reaserch, I learned that the link variable could be null during the iteration if the SelectNodes method returns a collection that contains elements other than <li> or <a> tags. In my original code, i’m selecting all <li> elements with <a> child elements, but if there are <li> elements without <a> child elements in the HTML document, the link variable would be null for those iterations.
To avoid this, I should have checked if the link variable is null before attempting to access its attributes. Additionally, checking if the href attribute is null before accessing its Value property is a good practice to avoid potential NullReferenceException.
Now i’m checking if the hrefAttribute != null and if it the condition is true, then the program is going to take out what we asked for. Here is how it looks after the small fix:
List<string> GetProductsLinks(string url)
{
List<string> productsLinks = new List<string>();
HtmlDocument htmlDocument = GetDocument(url);
HtmlNodeCollection linkNodes = htmlDocument.DocumentNode.SelectNodes("//li/a");
var baseUri = new Uri(url);
if (linkNodes != null)
{
foreach (var link in linkNodes)
{
var hrefAttribute = link.Attributes["href"];
if (hrefAttribute != null)
{
string href = hrefAttribute.Value;
productsLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
}
}
return productsLinks;
}
Now that i got all the links saved in a <list>, it was time to save those links in a text file so that the user would have acces to them. Here is where the library System.IO comes in place. After crating a new instance of StreamWriter we can now iterate in the list of links and copy them and paste them in a text file where the user would be able to acces them. I made sure that the system creates a new file everytime a user enters a new URL to scrape a website. After the scraping is completed the user would have acces to the file thru his downloads folder. Right now, the program only creates a .txt file. Here is the code below doing what I described.
void SaveLinksInFile(string filename, List<string> linksToSave)
{
StreamWriter writer = new StreamWriter(filename);
foreach (string link in linksToSave)
{
if (link.Contains("product"))
{
writer.WriteLine(link);
}
}
writer.Close();
}
Here is how the output looks like (for obvoius reasons the image that I’m providing is blured). The script scraped 101 links in one single page of a website. And saved them in a .txt file to be accesible for the user that is requesting that information.

I’m of course not done with the implementation of new functionalities to this Console Application. This blog post is going to be updated every single time a new functionality comes to live. The next functionality in mind, is saving data that a user requests from a website in a cvs file for database implementation.
![]()